Drupal 9+ et GraphQL 4
Je vous propose de revenir sur la version 4 du module GraphQL de Drupal et pourquoi cette nouvelle version va plus loin dans le découplage.
Parmi les choses que j'aime chez Drupal dans ses dernières versions c'est sa vision à long terme. Et notamment ses ambitions en terme de découplage. En effet, la communauté sort de plus en plus de son modèle monolithique historique pour se diriger vers une proposition d'outils pour les architectures découplées. Drupal, depuis sa version 8, s'envisage désormais comme un Content Management Framerwork (outil de gestion de contenu) plutôt qu'un Content Management System (système de gestion de contenu, ne me remerciez pas pour la traduction).
Et c'est dans ce cadre que je vais évoquer aujourd'hui le module GraphQL de Drupal dans sa dernière version (la version 4). En effet, cette dernière apporte des changements fondamentaux dans son implémentation et surtout dans sa philosophie. Et pour cause, cette version du module Drupal est tellement dédiée au découplage qu'elle permet d'envisager l'abandon de Drupal en tant que serveur GraphQL sans pour autant impliquer de modifications côté client. Du vrai découplé, du vrai long terme.

Avant toute chose
Qu'est-ce que GraphQL ?
Je ne vais pas revenir en détail sur l'histoire de GraphQL. Sachez cependant que GraphQL est un format de requêtes de données qui permet de limiter le nombre d'appels au serveur en permettant aux clients de ne requêter que les éléments nécessaires et de les organiser à leurs guises.
Concrètement, GraphQL vient challenger l'historique format de requêtes REST en permettant au client de requêter ses données de manière optimisée.
Là où REST nous offrait des endpoints pour chaque données (ou action) avec une structure bien définie, GraphQL va nous permettre d'interroger le serveur selon nos besoins.
Par exemple, prenons le type de données A, le type de données B qui contient un type de données C. En REST, il nous aurait fallu appeler 3 endpoints différents qui nous auraient permis d'obtenir toutes les données existantes délivrées par l'API, éventuellement avec un système de filtres, puis enfin, faire le tri des données ensuite côté client.
GraphQL en revanche va nous permettre de récupérer un peu de données A, toutes les données B ainsi qu'une partie des données C, et tout cela en un appel.
L'utilisation de GraphQL apporte donc plusieurs bénéfices :
- de meilleures performances (donc un plus faible impact environnemental) puisque le nombre de requêtes devient limité
- une facilitation du requêtage côté client (donc une meilleure maintenabilité).
Je vous encourage à vous renseigner sur GraphQL et notamment le module GraphQL de Drupal :
- https://graphql.org/learn/
- https://www.drupal.org/project/graphql
- https://drupal-graphql.gitbook.io/graphql/
Quelles nouveautés dans la version 4 ?
La version 4 de Drupal GraphQL apporte un vrai changement dans la philosophie de ce module. Comme je l'évoquais en introduction, elle a pour but de rendre son utilisation dans Drupal réellement "découplée".
Pour bien comprendre, il faut revenir à la version précédente du module. Celui-ci permettait d'activer des requêtes qui rendaient des données de manières structurées, en cohérence avec la structure de données de Drupal. On avait donc la possibilité de remonter une liste d'entités (par exemple des nodes) avec la possibilité de recevoir la liste dynamique des champs. Donc, lorsque vous créiez un nouveau champ, il était automatiquement disponible dans vos réponses GraphQL. De même pour la suppression. Tout ceci était donc super pratique, puisque Drupal fournissait très simplement une structure de données dynamique. Et évidemment, cette structure était basée sur celle de Drupal avec des champs 'field_' à la pelle.
Très pratique et très efficace donc, mais un découplé à sens unique puisque cette structure Drupalienne rend le Back indépendant, mais pas le Front. En effet, la logique du front doit alors se caler sur l'organisation de Drupal. Ce qui dans la logique du découplage est assez contre-intuitive.
C'est donc pour régler ce problème que la version 4 a récemment vu le jour. Elle a totalement repensé sa philosophie pour utiliser Drupal comme serveur de données mais pas comme organisateur de la donnée. Elle se base désormais uniquement sur un schema GraphQL. Ce schéma décrit la manière dont sont rendus les données, et ce schéma doit être décrit par les développeurs, donc le métier (et non l'outil). Une fois le schéma définit par le métier, le module GraphQL va uniquement fournir des outils pour rendre la donnée de manière à correspondre au dit schéma. Là encore, c'est au développeur d'intervenir.
Cela amène une contrainte forte puisque c'est beaucoup de code à fournir (mais vous allez voir c'est assez simple à prendre en main) pour obtenir une réponse clean. Mais c'est aussi un énorme gage de stabilité. Dans les versions précédentes du module, le changement d'un nom de champ coté Drupal impliquait une modification du client. Aujourd'hui ce n'est plus le cas, à partir du moment où le schéma ne change pas, pas de nécessité d'intervenir sur le front. Une modification d'un nom de champ côté Drupal n'a pas à impliquer de modifications de schéma, donc pas d'interventions sur le front. Du vrai découplé !
Mise en oeuvre
Préambule
La dernière version du module est récente (à l'heure où j'écris), et donc j'ai eu un peu de mal à rentrer dedans malgré les efforts de documentation que la communauté a fait à ce sujet. C'est pourquoi je vous propose de revenir pas à pas sur la manière dont fonctionne ce module, en reprenant par étapes le module d'exemple (graphql_examples) proposé par GraphQL.
Le but va être de fournir une api GraphQL qui va permettre de récupérer
- les données d'un node de type "Article"
- la liste des nodes de type "Article"
Pour cela on va partir de la définition du bundle "article" proposé par Drupal après une installation standard.
Par défaut, un Article est composé des champs suivants :
- Titre
- Corps (body)
- Image (field_image)
- Étiquettes (field_tags)
Pour aller plus loin, j'y ai ajouté un champs "Related articles" de type "Referenced entity" pour permettre de lier les articles entre eux.
Installation
Je ne vous ferais pas l'affront de vous décrire comment installer le module GraphQL. Une fois installé, vous aurez la possibilité d'accéder à l'interface qui va vous permettre de créer vos APIs GraphQL, dans Configuration > Webservices > GraphQL (/admin/config/graphql).
Sur cette page vous allez pouvoir créer autant de serveurs que vous aurez défini de schémas.
En cliquant sur le bouton "Créer un serveur", vous pourrez donc créer voter premier serveur, lui donner un nom et un endpoint, et... un schéma. Et donc pour cela nous allons devoir définir notre premier schema.
Nous allons donc commencer par créer un module dédié, qu'on appellera "my_schema" (N'hésitez pas à utiliser la commande drush drush generate module-standard). Par défaut ce module sera vide et on va venir petit à petit implémenter notre besoin. Et notre premier besoin est de créer un plugin qui référence notre schema.
Pour cela, il nous suffira de créer un plugin Schema (src/Plugin/GraphQL/Schema/MySchema.php) qui surcharge la classe SdlSchemaPluginBase tel que suit :
<?php
namespace Drupal\my_schema\Plugin\GraphQL\Schema;
use Drupal\graphql\GraphQL\ResolverRegistry;
use Drupal\graphql\Plugin\GraphQL\Schema\SdlSchemaPluginBase;
/**
* @Schema(
* id = "my_schema",
* name = "My Schema"
* )
*/
class MySchema extends SdlSchemaPluginBase {
/**
* {@inheritdoc}
*/
public function getResolverRegistry() {
// TODO: Implement getResolverRegistry() method.
$registry = new ResolverRegistry();
return $registry;
}
}
Dès lors, et après un petit `drush cr`, vous devriez voir votre schema apparaître dans la liste des schemas dans l'interface de création des serveurs. Notez bien que pendant la phase de développement, on va désactiver le cache sur notre serveur.
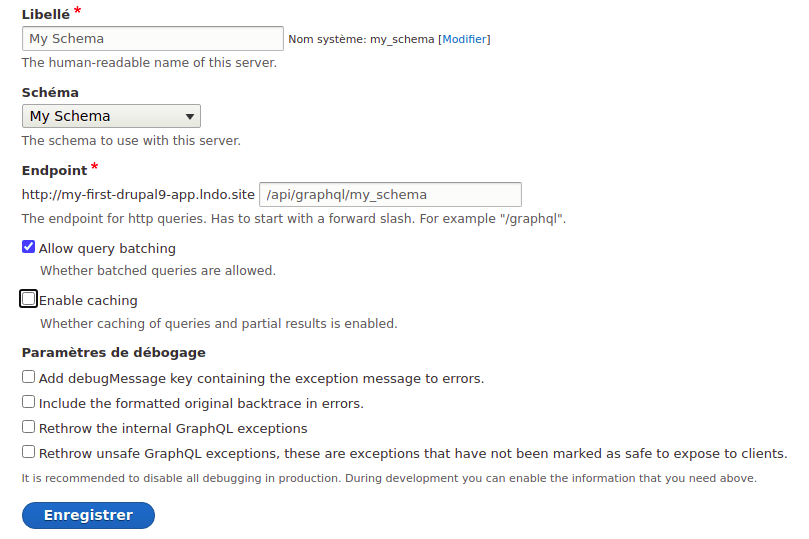
Voilà nous avons initialiser notre module et le plugin qui va référencer / définir notre schema. A ce stade, vous allez remarquer qu'il existe une erreur sur notre définition de schema et que vous ne pourrez pas utiliser tout de suite tous les outils mis à disposition par le module GraphQL. Mais c'est pour mieux introduire l'étape suivante : la définition du schéma.
Récupération d'un article
1. La définition du schéma
A ce stade nous avons référencé notre serveur cependant nous n'avons pas défini notre schéma. Vous l'aurez probablement remarqué si vous avez essayé d'utiliser l'interface de query fournie par le module GraphQL, et que vous avez obtenu l'erreur suivante :
Drupal\Component\Plugin\Exception\InvalidPluginDefinitionException: The module "my_schema" needs to have a schema definition "graphql/my_schema.graphqls"
Comme je l'évoquais en introduction, cette version 4 de GraphQL tourne autour d'un schema. Ce schema à pour but de contractualiser les échanges de données entre le front et le back et ce, sans créer de dépendances. C'est pourquoi ce schema n'est pas fournit par Drupal. Comprenez qu'il n'est pas généré par Drupal. C'est donc un fichier de définition .graphqls, un standard définit par GraphQL (https://graphql.org/learn/schema/) qui doit être implémenté et qui va servir de référence à notre serveur. Le plugin que nous avons créé précédemment va nous permettre uniquement de fournir les valeurs conformément au schema, mais en aucun cas il ne va venir altérer la définition du schema.
Donc, nous allons commencer par créer notre schema. Il doit être placé dans un répertoire "/graphql" à la racine de notre module, et être nommé par l'identifiant du schema que nous avons renseigné dans les annotations du plugin.
Nous allons donc créer un fichier "my_schema/graphql/my_schema.graphqls" qui, dans un premier temps, va définir la structure d'un article :
schema {
query: Query
}
type Query {
article(id: Int!): Article
}
type Article {
id: Int!
title: String!
}Pour le moment, nous n'allons fournir que l'identifiant et let titre de l'article. Nous alimenterons ce schema avec d'autres champs par la suite.
Une fois le schema associé au serveur ( et toujours le drush cr qui va bien), vous pouvez désormais accéder à l'interface de requête que fournit GraphQL dans "Configuration > Webservices > GraphQL > My Schema > Explorer" (/admin/config/graphql/servers/manage/my_schema/explorer).
Vous allez donc pouvoir y tester vos requêtes.
Conformément à la définition de notre schema, l'explorer nous indique les données disponibles (l'onglet "explorer" à gauche). Nous pouvons donc saisir notre première requête (dans l'onglet du milieu) qui va nous permettre de récolter les données de l'article ayant l'id 2 (par exemple). Et également, voir les résultats de la requête (dans l'onglet de droite).
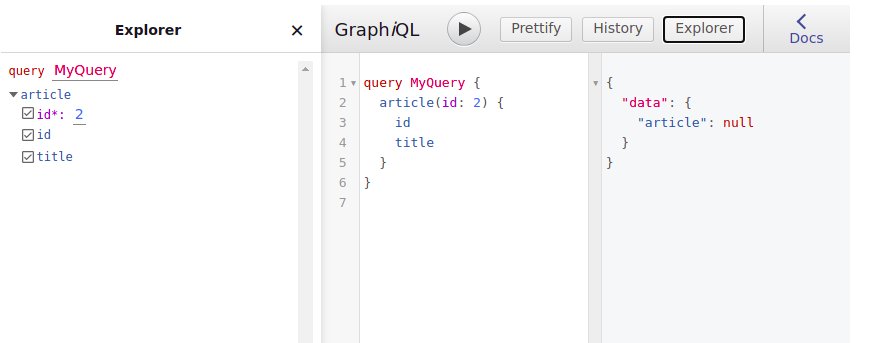
Comme vous pouvez le voir, pour le moment, aucune donnée ne remonte. C'est normal puisque nous n'avons pas encore renseigner la manière dont Drupal doit fournir les données pour le schema. Pour cela, passons à l'étape suivante, l'implémentation du schema.
2. Implémentation du schema
Maintenant que nous avons défini notre schema, nous devons fournir les données associées.
Pour cela, nous allons utiliser le système de "Data Producer" que fournit le module GraphQL. Les producers sont des plugins qui permettent de rendre une donnée en fonction de paramètres d'entrée. Et ce qui est intéressant c'est qu'on peut renseigner un paramètre d'entrée du producer grâce à une valeur en sortie d'un autre producer (dit comme ça, c'est abstrait, mais vous allez comprendre). Il existe déjà un bon nombre de producers fournit par le module GraphQL mais on peut évidemment en créer nous même, on reste dans le système de plugin de Drupal.
2.1 Récupérer un article
Dans un premier temps, nous allons définir la méthode de récupération de l'article demandé. Comme vous l'avez vu dans notre schema, la query article permet de remonter les données d'un seul article via son identifiant. Pour rappel :
type Query {
article(id: Int!): Article
}
Pour se faire nous allons intervenir dans notre plugin schema et ajouté la définition de la query article à l'objet $registry renvoyé par la méthode MySchema::getResolverRegistry(). Pour cela, je vais ajouter la méthode addArticleQuery qui prendra en paramètre le $registre et un paramètre $builder. Ce paramètre de type ResolverBuilder va nous permettre de construire notre données grâce aux producers.
On va donc modifier notre méthode getResolverRegistry() afin qu'elle appelle la méthode addArticleQuery de cette manière :
public function getResolverRegistry() {
// TODO: Implement getResolverRegistry() method.
$registry = new ResolverRegistry();
$builder = new ResolverBuilder();
$this->addArticleQuery($registry, $builder);
return $registry;
}
Et créer notre méthode addArticleQuery, dans laquelle on va ajouter au registry la manière dont on récupère un node article depuis son identifiant. On va donc utiliser la méthode addFieldResolver du $registry qui attend en paramètres :
- le type : 'Query'
- le champ : 'article'
- le resolver : le résultat de notre producer, soit la manière dont la valeur doit être récupérée.
Dans notre cas, nous allons utiliser le producer de type 'entity_load', qui comme son nom l'indique va permettre de récupérer une entité. Ce producer nécessite 3 paramètres (type, bundles, id) qu'on va renseigner grâce à la méthode map du producer. On obtient donc la méthode suivante :
/**
* Ajout de la query article.
*
* @param \Drupal\graphql\GraphQL\ResolverRegistry $registry
* Le registre.
* @param \Drupal\graphql\GraphQL\ResolverBuilder $builder
* Le resolver builder.
*/
protected function addArticleQuery(ResolverRegistry $registry, ResolverBuilder $builder) {
$registry->addFieldResolver(
'Query',
'article',
$builder->produce('entity_load')
->map('type', $builder->fromValue('node'))
->map('bundles', $builder->fromValue(['article']))
->map('id', $builder->fromArgument('id'))
);
}Revenons rapidement sur l'implémentation du producer. Ici on indique les 3 paramètres :
- le type : renseigné par une valeur 'node'. On utilise le builder pour indiquer qu'il s'agit d'une valeur brute : $builder->fromValue('node')
- les bundles : de la même manière on indique les bundles à requêter, dans notre cas un tableau d'une seule valeur 'article' : $builder->fromValue(['article'])
- l'id de l'entité : ici, on indique l'id du node à renvoyer, et cet id est fournit par le client, via un argument de requête 'id'. On utilise donc la méthode $builder->fromArgument('id')
Voilà, on vient de définir la manière dont on récupère l'entité pour notre query 'article'. Mais ce n'est pas suffisant, il nous faut désormais renseigner les champs qui vont composer notre article.
2.2 Récupérer les données de l'article
De la même manière, on va utiliser le registre et les producers pour renseigner nos données pour le type article. On va, dans un premier temps, modifier la méthode getResolverRegistry() afin d'y ajouter l'appel à la méthode $this->addArticleFields($registry, $builder); de la même manière et juste après l'appel à la méthode addArticleQuery.
Et ensuite on va renseigner les champs via le registre, toujours grâce à la méthode addFieldResolver et ses 3 paramètres :
- le type : Cette fois-ci 'article', puisqu'on va venir enrichir le type 'Article' du schema.
- le champ : 'id' et 'title'
- le resolver : le résultat de notre producer, soit la manière dont la valeur doit être récupérée.
Notez qu'ici on va utiliser des producer existant différents pour chaque type :
- id : le producer "entity_id" qui prend en paramètre une entité (entity)
- title : le producer "entity_label" qui prend également en paramètre une entité (entity)
Dans notre cas, l'entité passée en paramètre sera l'article courant, celui pour lequel GraphQL essai de rendre les champs. On utilisera donc $builder->fromParent() qui va nous renvoyer les résultats de la query parent, dans notre cas la query 'article', donc le resolver résultant du producer qui nous renvoie un article, qu'on a défini justement dans la méthode addArticleQuery.
/**
* Ajout des champs d'un article.
*
* @param \Drupal\graphql\GraphQL\ResolverRegistry $registry
* Le registre.
* @param \Drupal\graphql\GraphQL\ResolverBuilder $builder
* Le resolver builder.
*/
protected function addArticleFields(ResolverRegistry $registry, ResolverBuilder $builder) {
// Champs id
$registry->addFieldResolver(
'Article',
'id',
$builder->produce('entity_id')
->map('entity', $builder->fromParent())
);
// Champs title
$registry->addFieldResolver(
'Article',
'title',
$builder->produce('entity_label')
->map('entity', $builder->fromParent())
);
}Et voilà, on a renseigné nos deux premiers champs. Je vous avoue qu'à première vue, ça m'a paru bien compliqué pour juste rendre une donnée, mais une fois qu'on a assimilé le principe de producer, c'est assez efficace. Encore une fois ça peut paraître assez lourd, très générateur de code, mais c'est pour la bonne cause, la longévité de votre produit.
Maintenant, nous avons enfin notre premier résultat qui remonte dans l'explorateur :
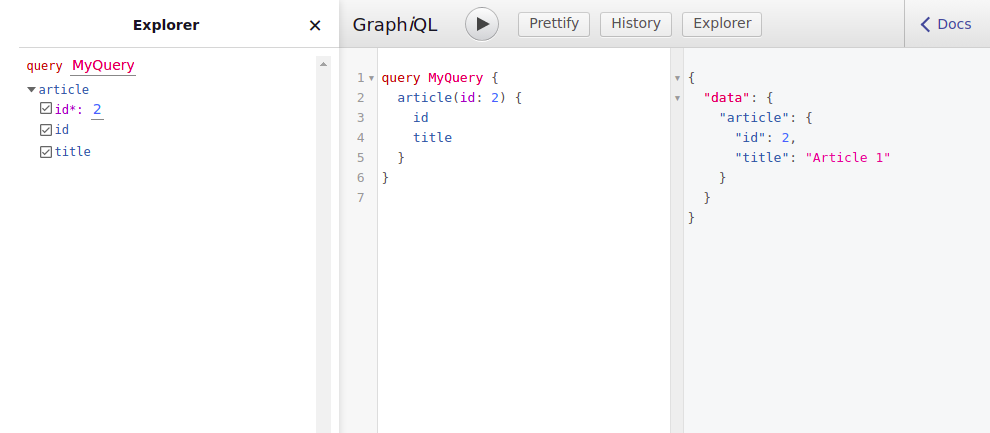
(oui je sais, mon article avec l'id 2 s'appelle "Article 1"...)
3. Ajout du champ body : création d'un Data Producer
Sur le même principe que les étapes précédentes, on va maintenant pouvoir ajouter le champ body. On va donc procéder en deux étapes :
- la modification du schéma, afin d'indiquer au front qu'on modifie la structure de la réponse.
- la modification du registre, pour renseigner les données du body.
3.1 Modifier le schema
Rien de bien compliqué ici, on va uniquement ajouter le champs body dans la structure d'un Article. Donc dans notre schema my_schema.graphqls, on va tout simplement ajouter une donnée, cette fois-ci nullable. Pour bien comprendre l'intérêt du schema, je vais appeler ce champs "content" et non "body". Ainsi, on va plus facilement saisir l'intérêt du découplage et l'indépendance du schema par rapport à la structure Drupal.
type Article {
id: Int!
title: String!
content: String
}
Après un drush cr, normalement l'explorer doit vous proposer le champ "content", avec une valeur null évidemment, puisque nous n'avons pas renseigné de valeur de champ dans le registre.
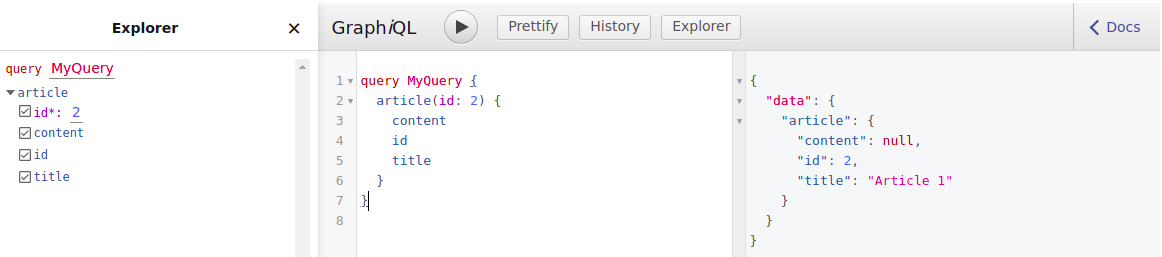
3.2 Ajout du champ dans le registre
Pour indiquer à GraphQL que le champ "content" du schema sera renseigné par la valeur du champ body, on va modifier le registre resolver sur le modèle des champs "id" et "title". La différence ici c'est que le champ body est un champ complexe. En base il est structuré avec différents champs qui comprennent la valeur ainsi que le format de l'éditeur. Dans notre cas, on veut rendre un markup, un string html basique, pas de structure complexe.
Avant de commencer, il est utile de préciser que dans ce cas on pourrait utiliser un producer déjà existant 'property_path', qui nous aurait permit d'aller chercher la valeur brute du champ "body.value". Le problème ici, c'est qu'on ne veut pas uniquement la valeur brute, on veut aussi utiliser les outils des "processed_text" pour rendre un DOM terminé, utilisable en l'état par n'importe quel outil hors Drupal.
Pour info, je vous mets ici l'exemple de ce que ça aurait donné:
$registry->addFieldResolver('Article', 'body',
$builder->produce('property_path')
->map('type', $builder->fromValue('entity:node'))
->map('value', $builder->fromParent())
->map('path', $builder->fromValue('body.value'))
Revenons à nos moutons. Pour obtenir un markup propre ("processed"), nous allons utiliser la méthode "\Drupal\filter\Element\ProcessedText::preRenderText", et pour l'appeler dans notre contexte GraphQL, nous allons créer notre propre data producer. Comme évoqué plus tôt, les data producers sont des Plugins qui vont permettre de rendre une donnée en fonction de paramètres d'entrée. Dans notre cas, la méthode preRenderText prend en entrée un tableau qui doit contenir principalement le format de texte utilisé, le texte et la langue. Nous allons donc définir ces 3 paramètres en entrée de notre Data Producer. Le fichier du Plugin que nous allons créer sera donc celui-ci :
<?php
namespace Drupal\my_schema\Plugin\GraphQL\DataProducer;
use Drupal\Core\Render\RenderContext;
use Drupal\filter\Element\ProcessedText;
use Drupal\graphql\Plugin\GraphQL\DataProducer\DataProducerPluginBase;
/**
* @DataProducer(
* id = "processed_text",
* name = @Translation("Processed text"),
* description = @Translation("Render processed text."),
* produces = @ContextDefinition("any",
* label = @Translation("Processed text")
* ),
* consumes = {
* "text" = @ContextDefinition("string",
* label = @Translation("Text"),
* required = TRUE
* ),
* "format" = @ContextDefinition("string",
* label = @Translation("Text format"),
* required = TRUE
* ),
* "langcode" = @ContextDefinition("string",
* label = @Translation("Langcode"),
* required = FALSE
* ),
* "filter_types_to_skip" = @ContextDefinition("array",
* label = @Translation("Filter types to skip"),
* required = FALSE
* )
* }
* )
*/
class ProcessedTextProducer extends DataProducerPluginBase {
/**
* Resolver.
*
* @param string $text
* The text.
* @param string $format
* The format.
* @param null $langcode
* The langcode.
* @param array $filterTypesToSkip
* The filter to skip.
*
* @return string
* The processed text.
*/
public function resolve($text, $format, $langcode = NULL, $filterTypesToSkip = null) {
}
}
Maintenant, concentrons nous sur l'appel à ce producer dans le registre. Notre producer "processed_text" prend 4 paramètres en entrée. Dans notre cas, la valeur de ces paramètres seront celle du champ body (body.value et body.format). Pour aller chercher ces données, nous allons donc utiliser le producer "property_path" qui nous permet de récupérer les données d'une propriété de notre entity, selon un "property path" (comme son nom l'indique). Donc dans notre méthode 'MySchema::addArticleFields', nous allons ajouter les lignes suivantes qui vont nous permettre d'ajouter notre champ content au registre :
// Champ content
$registry->addFieldResolver(
'Article',
'content',
$builder->produce('processed_text')
->map('text', $builder->produce('property_path')
->map('type', $builder->fromValue('entity:node'))
->map('value', $builder->fromParent())
->map('path', $builder->fromValue('body.value'))
)
->map('format', $builder->produce('property_path')
->map('type', $builder->fromValue('entity:node'))
->map('value', $builder->fromParent())
->map('path', $builder->fromValue('body.format'))
)
->map('langcode', $builder->produce('property_path')
->map('type', $builder->fromValue('entity:node'))
->map('value', $builder->fromParent())
->map('path', $builder->fromValue('langcode.value'))
)
);A cette étape, nous appelons notre Data Producer "processed_text", et c'est la méthode "ProcessedTextProducer::resolve" qui va être notre point d'entrée.
Dernière subtilité et non des moindres, notre réponse GraphQL est de type CacheableJsonResponse. Si bien que l'utilisation de la méthode "\Drupal\filter\Element\ProcessedText::preRenderText" va nous poser le fameux problème de la LogicException du EarlyRenderingControllerWrapperSubscriber:
LogicException: The controller result claims to be providing relevant cache metadata, but leaked metadata was detected. Please ensure you are not rendering content too early.
Je ne vais pas m'attarder ici sur le sujet, mais il s'agit du fait que la méthode en question va générer des dépendances de cache dans un contexte de rendu. Or nous ne sommes pas dans un contexte de rendu habituel et donc on obtiendra une LogicException. Ici, nous avons juste besoin de cette méthode pour rendre un markup, donc je vais aller assez vite. Pour éviter cela, nous allons utiliser la méthode de Lullabot qui consiste à créer un contexte temporaire pour générer un markup. Le markup final n'a plus de dépendance, et le contexte utilisé n'est pas le contexte final. Vous retrouverez l'article ici https://www.lullabot.com/articles/early-rendering-a-lesson-in-debugging-drupal-8.
Tout ça pour dire qu'au final, notre méthode va ressembler à ceci :
public function resolve($text, $format, $langcode = NULL, $filterTypesToSkip = null) {
$filterTypesToSkip = $filterTypesToSkip ?? [];
$content = \Drupal::service('renderer')->executeInRenderContext(
new RenderContext(),
function () use ($text, $format, $langcode, $filterTypesToSkip) {
$processedText = ProcessedText::preRenderText(
[
'#text' => $text,
'#format' => $format,
'#langcode' => $langcode,
'#filter_types_to_skip' => $filterTypesToSkip,
]
);
return $processedText['#markup'];
});
return $content;
}Voilà, nous rendons désormais notre content depuis le champ body.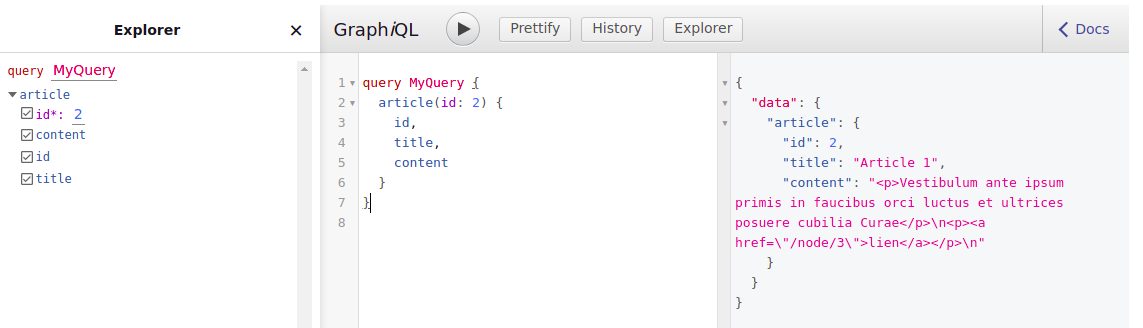
4. Le champs de l'image
Dans l'exemple précédent, on "chaînait" les producers "processed_text" et "property_path" pour récupérer les données de l'un pour les passer à l'autre. Pour la récupération de l'url de l'image, on va être dans le même cas puisqu'on va avoir besoin de récupérer l'url (producer "image_url"), de l'entité fichier (producer "entity_loader"), via l'id du champ field_image (producer "property_path"). Je vais vous montrer ici qu'on peut utiliser la méthode "compose" du builder pour arriver à notre fin. Le résultat est le même que le "chaînage" précédemment utilisé, mais la méthode est peut-être un peu plus élégante, notamment quand on va avoir beaucoup d'étapes à assembler.
Première étape, pour ajouter le champ image, on modifie le schema (c'est la règle !).
type Article {
id: Int!
title: String!
content: String
image: String
}On ajoute ensuite notre champ au registre de via la composition de producer :
// Champ image
$registry->addFieldResolver(
'Article',
'image',
$builder->compose(
// Load le target ID.
$builder->produce('property_path')
->map('type', $builder->fromValue('entity:node'))
->map('value', $builder->fromParent())
->map('path', $builder->fromValue('field_image.target_id')),
// Load le file
$builder->produce('entity_load')
->map('type', $builder->fromValue('file'))
->map('id', $builder->fromParent()),
// Load l'url du fichier
$builder->produce('image_url')
->map('entity', $builder->fromParent()
)
)
);Notez ici que chaque argument de la méthode compose est un producer. Et donc, via la composition, la valeur du parent ($builder->formParent()) est la valeur retournée par le précédent argument de la composition.
On obtient ainsi l'url de notre image pour l'article :
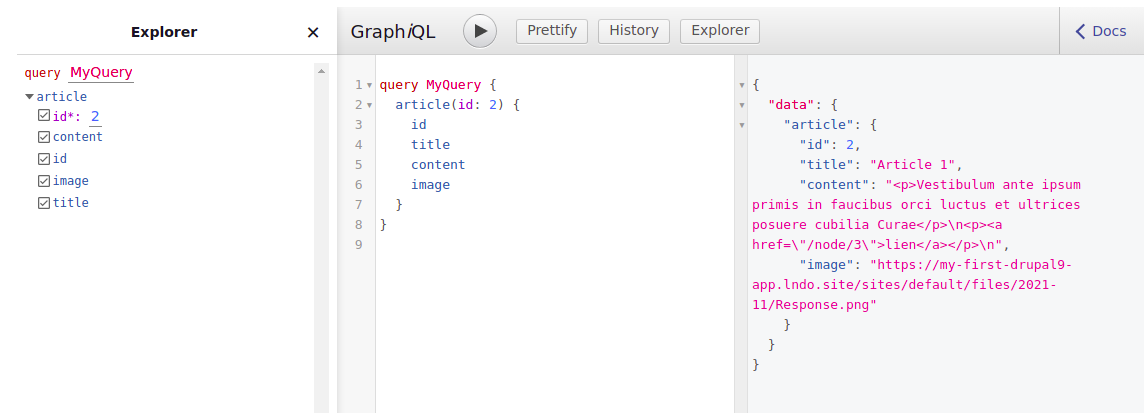
Récupération une liste d'articles
Nous savons maintenant récupérer les données d'un article. Nous allons à présent récupérer une liste de plusieurs articles. Pour cela nous allons utiliser la méthode décrite dans le module graphql_examples proposé par le module graphql. Cette méthode permet de récupérer l'ensemble des articles en passant en paramètres l'offset et la limite (obligatoire) de liste. Nous allons apporter deux modifications à cette méthode pour nous permettre de rendre la limite facultative, ainsi que de nous donner la possibilité de filtrer la liste via un paramètre ids.
1. La modification du schéma
Evidemment, nous allons commencer par modifier notre schema en y ajoutant la query articles (avec un s). Cette query rendra un élément de type ArticleConnection. Ce dernier permettra de récupérer le total (le nombre d'élément total uniquement) et la liste d'articles via le champ item. On va donc modifier notre type Query, et ajouter le type ArticleConnection, comme ceci :
type Query {
article(id: Int!): Article
articles(
offset: Int = 0
limit: Int = 0
ids: [Int!] = null
): ArticleConnection!
}
type ArticleConnection {
total: Int!
items: [Article!]
}
2. Le data producer
Maintenant que notre schema est défini, nous allons pouvoir créer notre data producer. Vous l'aurez compris, il prendra 3 paramètres d'entrées qui seront passés par argument.
<?php
namespace Drupal\my_schema\Plugin\GraphQL\DataProducer;
use Drupal\Core\Cache\RefinableCacheableDependencyInterface;
use Drupal\Core\Entity\EntityTypeManagerInterface;
use Drupal\Core\Plugin\ContainerFactoryPluginInterface;
use Drupal\graphql\Plugin\GraphQL\DataProducer\DataProducerPluginBase;
use Symfony\Component\DependencyInjection\ContainerInterface;
use Drupal\my_schema\Wrappers\QueryConnectionWrapper;
/**
* @DataProducer(
* id = "query_articles",
* name = @Translation("Load articles"),
* description = @Translation("Loads a list of articles."),
* produces = @ContextDefinition("any",
* label = @Translation("Article connection")
* ),
* consumes = {
* "offset" = @ContextDefinition("integer",
* label = @Translation("Offset"),
* required = FALSE
* ),
* "limit" = @ContextDefinition("integer",
* label = @Translation("Limit"),
* required = FALSE
* ),
* "ids" = @ContextDefinition("any",
* label = @Translation("List of ids"),
* required = FALSE
* ),
* }
* )
*/
class QueryArticles extends DataProducerPluginBase implements ContainerFactoryPluginInterface {
const MAX_LIMIT = 100;
/**
* @var \Drupal\Core\Entity\EntityTypeManagerInterface
*/
protected $entityTypeManager;
/**
* {@inheritdoc}
*
* @codeCoverageIgnore
*/
public static function create(ContainerInterface $container, array $configuration, $plugin_id, $plugin_definition) {
return new static(
$configuration,
$plugin_id,
$plugin_definition,
$container->get('entity_type.manager')
);
}
/**
* Articles constructor.
*
* @param array $configuration
* The plugin configuration.
* @param string $pluginId
* The plugin id.
* @param mixed $pluginDefinition
* The plugin definition.
* @param \Drupal\Core\Entity\EntityTypeManagerInterface $entityTypeManager
*
* @codeCoverageIgnore
*/
public function __construct(
array $configuration,
$pluginId,
$pluginDefinition,
EntityTypeManagerInterface $entityTypeManager
) {
parent::__construct($configuration, $pluginId, $pluginDefinition);
$this->entityTypeManager = $entityTypeManager;
}
/**
* @param int $offset
* @param int $limit
* @param null $ids
* @param \Drupal\Core\Cache\RefinableCacheableDependencyInterface|null $metadata
*
* @return \Drupal\my_schema\Wrappers\QueryConnectionWrapper
* @throws \Drupal\Component\Plugin\Exception\InvalidPluginDefinitionException
* @throws \Drupal\Component\Plugin\Exception\PluginNotFoundException
*/
public function resolve($offset, $limit, $ids = NULL, RefinableCacheableDependencyInterface $metadata = NULL) {
$storage = $this->entityTypeManager->getStorage('node');
$entityType = $storage->getEntityType();
$query = $storage->getQuery()
->currentRevision()
->accessCheck();
$query->condition($entityType->getKey('bundle'), 'article');
if ($offset || $limit) {
$query->range($offset, $limit !== 0 ? $limit : static::MAX_LIMIT );
}
if (isset($ids)) {
$query->condition($entityType->getKey('id'), empty($ids) ? [-1] : $ids, 'IN');
}
$metadata->addCacheTags($entityType->getListCacheTags());
$metadata->addCacheContexts($entityType->getListCacheContexts());
return new QueryConnectionWrapper($query);
}
}
Rien de bien nouveau ici. Il faut toutefois noter que le module graphql_examples utilise un wrapper afin d'extraire la notion des champs 'total' et 'items'. Sur ce modèle, on crée donc une class QueryConnectionWrapper, qui n'est pas un Plugin pour le coup, c'est juste un outil interne.
<?php
namespace Drupal\my_schema\Wrappers;
use Drupal\Core\Entity\Query\QueryInterface;
use GraphQL\Deferred;
/**
* Helper class that wraps entity queries.
*/
class QueryConnectionWrapper {
/**
* @var \Drupal\Core\Entity\Query\QueryInterface
*/
protected $query;
/**
* QueryConnection constructor.
*
* @param \Drupal\Core\Entity\Query\QueryInterface $query
*/
public function __construct(QueryInterface $query) {
$this->query = $query;
}
/**
* @return int
*/
public function total() {
$query = clone $this->query;
$query->range(NULL, NULL)->count();
return $query->execute();
}
/**
* @return array|\GraphQL\Deferred
*/
public function items() {
$result = $this->query->execute();
if (empty($result)) {
return [];
}
$buffer = \Drupal::service('graphql.buffer.entity');
$callback = $buffer->add($this->query->getEntityTypeId(), array_values($result));
return new Deferred(function () use ($callback) {
return $callback();
});
}
}
Pour le champ items, on utilise le service graphql.buffer.entity qui va rendre les entités en fonction de la liste d'ids passée.
3. L'ajout au registre.
Il ne nous reste plus maintenant qu'à ajouter notre query et notre type ArticleConnection au registre. Pour cela, retour au plugin MySchema, où on va ajouter l'appel à une méthode $this->addArticlesQuery($registry, $builder); dans getResolverRegistry qui va enregistrer notre query :
/**
* Ajout de la query articles.
*
* @param \Drupal\graphql\GraphQL\ResolverRegistry $registry
* Le registre.
* @param \Drupal\graphql\GraphQL\ResolverBuilder $builder
* Le resolver builder.
*/
protected function addArticlesQuery(ResolverRegistry $registry, ResolverBuilder $builder) {
// Define articles type.
$registry->addFieldResolver('Query', 'articles',
$builder->produce('query_articles')
->map('offset', $builder->fromArgument('offset'))
->map('limit', $builder->fromArgument('limit'))
->map('ids', $builder->fromArgument('ids'))
);
}
Et de la même manière, on va ajouter notre type ArticleConnection. Comme celui-ci est lié à notre objet QueryConnectionWrapper, on va appeler une méthode générique $this->addConnectionFields('ArticleConnection', $registry, $builder); dans getResolverRegistry :
/**
* Add connection fields
*
* @param string $type
* Le type.
* @param \Drupal\graphql\GraphQL\ResolverRegistry $registry
* Le registre.
* @param \Drupal\graphql\GraphQL\ResolverBuilder $builder
* Le builder
*/
protected function addConnectionFields(string $type, ResolverRegistry $registry, ResolverBuilder $builder) {
$registry->addFieldResolver($type, 'total',
$builder->callback(function (QueryConnectionWrapper $connection) {
return $connection->total();
})
);
$registry->addFieldResolver($type, 'items',
$builder->callback(function (QueryConnectionWrapper $connection) {
return $connection->items();
})
);
}Et voilà, nous pouvons désormais appeler notre query et obtenir une liste de résultats : 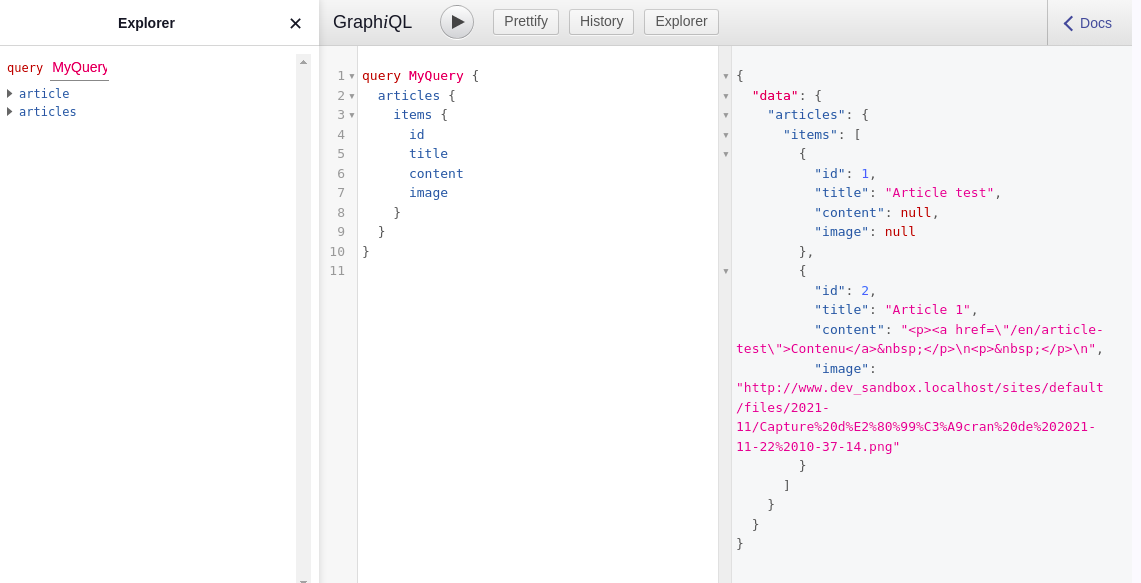
Conclusion
Au final, après une utilisation somme toute très légère, j'ai un double avis.
Premièrement, je trouve la philosophie géniale. Avoir fait évoluer un module (qui au passage n'est pas rétrocompatible) pour permettre à celui-ci de répondre à un potentiel besoin de se soustraire à lui-même, c'est typiquement ce que j'aimerai que la technologie en général propose de plus en plus. Vous l'aurez compris, les systèmes dépendants et fermés ne sont pas ma tasse de thé. Attention, il faut bien comprendre aussi que le fait de baser graphQL sur le principe du schema, ce n'est pas uniquement dans le but de remplacer facilement Drupal par un autre serveur graphQL sans impact. Ce système permet aussi à Drupal de remplacer facilement n'importe quel autre serveur graphQL. Toujours est-il que ce module va dans le sens du framework que veut devenir Drupal, plus qu'un éco-système.
Deuxièmement, c'est assez lourd. Pour ce petit exemple, on a généré énormément de lignes. On est bien loin de la tendance du no-code ou du low-code. Pour l'instant, c'est assez complexe à prendre en main. Il y a toute une notion de cache que je n'ai pas forcément abordée (parce que je ne l'ai pas encore très bien appréhendée). Je n'ai pas encore eu le temps de m'attaquer aux mutations, mais ça risque d'être également assez lourd en terme de production de code. Le module est encore jeune et je pense que des outils vont voir le jour pour faciliter cela. En même temps, il faut bien se dire que ces lignes de codes sont là pour durer. Donc si c'est le prix pour avoir un service qui dure dans le temps, je veux bien le payer. En revanche, si vous travailler sur une application éphémère, et que vous voulez servir de la donnée via GraphQL, m'est avis que vous devriez plutôt partir sur la version 3. En tout cas, avec cette version, vous pouvez maintenant maîtriser complètement votre API GraphQL.
Sources
Vous trouverez les sources de cette prise en main ici : https://github.com/tsecher/graphql4_example